7.3 KiB
第一章——Docker
容器是怎么隔离的
进程:一些数据加上代码本身的二进制文件,放在磁盘上,就是我们平常所说的一个“程序”,也叫代码的可执行镜像(executable image)。
程序运起来后的计算机执行环境的总和,就是:进程。
“程序”运行起来,就从磁盘上的二进制文件,变成了计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。
静态的表现是程序,动态的表现是进程,容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。
Cgroups 技术是用来制造约束的主要手段,而Namespace 技术则是用来修改进程视图的主要方法。
Cgroups :其名称源自控制组群(control groups)的简写,是Linux内核的一个功能,用来限制、控制与分离一个进程组的资源(如CPU、内存、磁盘输入输出等)。
在Linux启动一个容器
$ docker run -it busybox /bin/sh
/ #
**docker run:**启动容器
**-it:**分配一个文本输入/输入环境,也就是TTY,这样就可以和容器交互
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
10 root 0:00 ps
**注释:**执行ps指令,我们在Docker 里最开始执行的 /bin/sh,就是这个容器内部的第 1 号进程(PID=1),而这个容器里一共只有两个进程在运行。这就意味着,前面执行的 /bin/sh,以及我们刚刚执行的 ps,已经被 Docker 隔离在了一个跟宿主机完全不同的世界当中。
这种技术,就是 Linux 里面的 Namespace 机制。
在 Linux 系统中创建线程的系统调用是 clone(),创建一个新进程时,就可以在参数中指定 CLONE_NEWPID 参数,比如:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
这时,新创建的这个进程将会“看到”一个全新的进程空间,在这个进程空间里,它的 PID 是 1。之所以说“看到”,是因为这只是一个“障眼法”,在宿主机真实的进程空间里,这个进程的 PID 还是真实的数值,比如 100。
除了 PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。
**IPC:**隔离System V IPC和POSIX消息队列。 **Network:**隔离网络资源。 **Mount:**隔离文件系统挂载点。每个容器能看到不同的文件系统层次结构。 **PID:**隔离进程ID。 **UTS:**隔离主机名和域名。 **User:**隔离用户ID和组ID。
这,就是 Linux 容器最基本的实现原理,容器,其实就是一种特殊的进程。
关于namespace
namespace的API包括clone()、setns()以及unshare(),还有/proc下的部分文件。为了确定隔离的到底是哪种namespace,在使用这些API时,通常需要指定以下六个常数的一个或多个,通过|(位或)操作来实现。这六个参数分别是CLONE_NEWIPC、CLONE_NEWNS、CLONE_NEWNET、CLONE_NEWPID、CLONE_NEWUSER和CLONE_NEWUTS。
- 通过clone()创建新进程的同时创建namespace
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
参数child_func传入子进程运行的程序主函数。
参数child_stack传入子进程使用的栈空间
参数flags表示使用哪些CLONE_*标志位
参数args则可用于传入用户参数
clone()实际上是传统UNIX系统调用fork()的一种更通用的实现方式,它可以通过flags来控制使用多
少功能。一共有二十多种CLONE_*的flag(标志位)参数用来控制clone进程的方方面面(如是否与父
进程共享虚拟内存等等)。
- 通过setns()加入一个已经存在的namespace
在进程都结束的情况下,也可以通过挂载的形式把namespace保留下来,保留namespace的目的自然是
为以后有进程加入做准备。通过setns()系统调用,你的进程从原先的namespace加入我们准备好的新
namespace,使用方法如下:
int setns(int fd, int nstype)
参数fd表示我们要加入的namespace的文件描述符。上文已经提到,它是一个指向/proc/[pid]/ns目录
的文件描述符,可以通过直接打开该目录下的链接或者打开一个挂载了该目录下链接的文件得到。
参数nstype让调用者可以去检查fd指向的namespace类型是否符合我们实际的要求。如果填0表示不检查。
复制代码
- 通过unshare()在原先进程上进行namespace隔离
后要提的系统调用是unshare(),它跟clone()很像,不同的是,unshare()运行在原先的进程上,
不需要启动一个新进程,使用方法如下:
int unshare(int flags);
调用unshare()的主要作用就是不启动一个新进程就可以起到隔离的效果,相当于跳出原先的
namespace进行操作。这样,你就可以在原进程进行一些需要隔离的操作。Linux中自带的
unshare命令,就是通过unshare()系统调用实现的。
如下Docker源码,呈现了namespace的创建过程。

虚拟机和容器的对比图
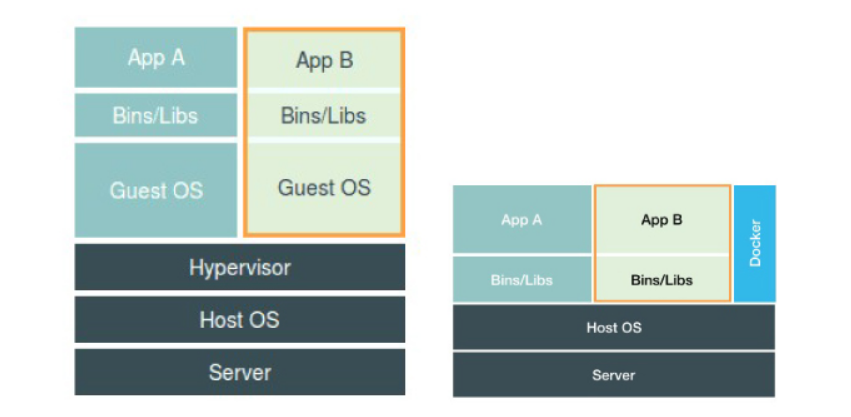
**Hypervisor:**是虚拟机最主要的部分。它通过硬件虚拟化功能,模拟出了运行一个操作系统需要的各种硬件,比如 CPU、内存、I/O 设备等等。然后,它在这些虚拟的硬件上安装了一个新的操作系统,即 Guest OS。
有种对比图是这样的
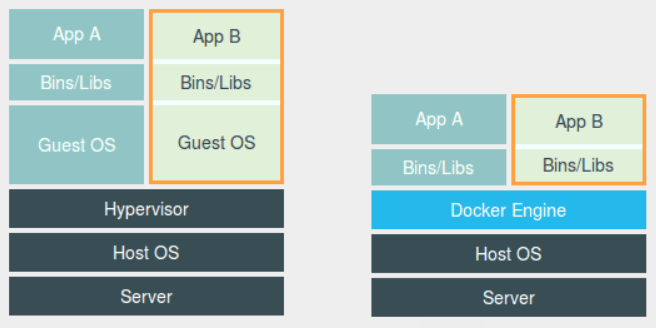
但是这样并不严谨,Docker Engine不像 Hypervisor 那样对应用进程的隔离环境负责,也不会创建任何实体的“容器”,真正对隔离环境负责的是宿主机操作系统本身。
用户运行在容器里的应用进程,跟宿主机上的其他进程一样,都由宿主机操作系统统一管理,只不过这些被隔离的进程拥有额外设置过的 Namespace 参数。而 Docker 项目在这里扮演的角色,更多的是旁路式的辅助和管理工作。
这样的架构也解释了为什么 Docker 项目比虚拟机更受欢迎的原因。
虚拟机里面必须运行一个完整的 Guest OS 才能执行用户的应用进程。这就不可避免地带来了额外的资源消耗和占用。一般情况下虚拟机自己就需要占用 100~200 MB 内存。
深入理解容器镜像
挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。
一个最常见的 rootfs,或者说容器镜像,会包括如下所示的一些目录和文件:
$ ls /
bin dev etc home lib lib64 mnt opt proc root run sbin sys tmp usr var
对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)。
这样,一个完整的容器就诞生了。当然内核还是共享宿主机操作系统的内核。